Lorsque l’on étudie un flux en détail, par exemple pour rédiger une spécification fonctionnelle détaillée, on part très souvent de l’observation des données gérées dans les transactions standard pour analyser l’éventail des données disponibles.
Prenons un exemple, je lance l’état dynamique des stocks (MD04) et je cherche les tables qui contiennent les données de prévisions.
Pour avoir une analyse complète des tables utilisées par ce programme j’utilise la trace SQL, avec la transaction ST05. Dans cette optique, je fais une utilisation minimale de ce programme mais amplement suffisante pour mon besoin. La trace SQL me remonte bien l’ensemble des tables lues, mais par contre je n’ai aucune idée du contenu des tables lues. Et ce serait bien pratique de savoir à partir de quelles tables les données ont été lues.
La question est « Mais d’où est-ce qu’elle vient cette donnée ? »
L’idée que j’imagine est de reprendre les résultats issus de la trace SQL pour refaire la lecture de chaque table en appliquant les mêmes critères de sélection. Comme ceci je pourrais visualiser les données lues.
La trace SQL me donne un tableau avec les données suivantes pour chaque accès à la base de données :
VBBE SELECT WHERE "MANDT" = '140' AND "MATNR" = '1234567' AND "WERKS" = '1000' VBBS SELECT WHERE "MANDT" = '140' AND "MATNR" = '1234567' AND "WERKS" = '1000' MDPB SELECT WHERE "MANDT" = '140' AND "MATNR" = '1234567' AND "WERKS" = '1000' AND "VERVS" = 'X' AND NOT ( "PLNMG" = 0 ) MDRS SELECT WHERE "MANDT" = '140' AND "MATNR" = '1234567' AND "WERKS" = '1000' AND "XLOEK" = '' AND "KZEAR" = ''
- TABLE : MDPB
- CLAUSE : SELECT WHERE « MANDT » = ‘140’ AND « MATNR » = ‘1234567’ AND « WERKS » = ‘1000’ AND « VERVS » = ‘X’ AND NOT ( « PLNMG » = 0 )
C’est largement exploitable pour mon utilitaire.
Il faut donc que j’arrive à écrire une clause de lecture à partir des infos recueillies par la trace SQL.
SELECT *
FROM MDPB
WHERE MATNR = '1234567' AND WERKS = '1000' AND VERVS = 'X'
AND NOT ( PLNMG = 0 ).
ENDSELECT.Évidement toute la difficulté sera de pouvoir exécuter tous les SELECT identifiés dans la trace SQL sans avoir à les écrire un à un, sinon ce n’est pas exploitable.
De quoi ai je besoin pour faire ce travail ?
Je sais d’entrée de jeu que cela va faire appel à du code ABAP « dynamique ». Cela ne me fait pas trop peur, je continue.
En premier il faut récupérer la trace SQL en l’exportant dans un tableur, bon ça c’est fait !
Ensuite je dois écrire un programme pour faire tous les SELECT en créant un code générique qui permettra d’exécuter toutes les clauses en dynamique.
Pour commencer je vais devoir définir dans le SELECT la table à lire à partir du nom qui me sera donné sous forme d’un texte.
FROM (NOM_DE_LA_TABLE TABLE)
Il suffira de mettre la variable qui contient le nom de la table entre parenthèses, OK, passons à la suite.
Ensuite il faudra aussi gérer dynamiquement le filtre de sélection. Pour cela je n’aurai qu’à mettre la clause de la trace SQL entre parenthèse dans le code du SELECT, ce qui donnera le code suivant :
WHERE (CLAUSE).
A l’exécution du programme, l’ABAP va copier la clause pour l’exécuter. Schématiquement le code sera alors le suivant : WHERE "MANDT" = '140' AND "MATNR" = 'VINA' AND "WERKS" = '1000' AND "VERVS" = 'X' AND NOT ( "PLNMG" = 0 ). Pour être exact, il faudra enlever les guillemets qui encadrent les noms des champs. A part ce détail la clause sera parfaitement valide, Bon on avance. Continuons !
Ensuite il me faudra une variable qui me servira à stocker les données extraites de la base de données. Pour créer cette variable, je vais utiliser le Run Time Type Service (RTTS). Cette fonctionnalité me permettra de créer une variable typée correctement en partant simplement du nom de la table. Grosso modo au lieu de créer des données à chaque fois que je dois lire une table (DATA: MDPB TYPE MDPB.) ce qui serait bien trop rigide, je vais créer une variable générique que je pourrais réutiliser autant de fois que nécessaire pour la typer dynamiquement en utilisant le RTTS sus-cité.
Je crée une variable générique de la manière suivante
DATA: GENERIC type ref to DATA.
Ensuite je crée un Field-symbol lui aussi générique avec le type ANY. Les field-symbols sont des sortes de variables. Ils sont nécessaires pour, d’une certaine manière, matérialiser le type de donnée qui sera modélisé par la variable « GENERIC ».
FIELD-SYMBOLS : <FS_ANY> type ANY.
Ensuite j’utilise le RTTS pour typer ma donnée dynamique. J’entoure tout ceci d’un bloc TRY pour gérer l’erreur au cas où le nom de la table récupérée dans le fichier source ne serait pas correct. Si je ne prends pas cette précaution c’est le DUMP assuré !
TRY.
CREATE DATA GENERIC TYPE (NOM_DE_LA_TABLE). "<= C'est ça le RTTS
CATCH CX_SY_CREATE_DATA_ERROR.
< indiquer à l'utilisateur le plantage et passer à la lecture suivante >
ENDTRY.
ASSIGN GENERIC->* TO <FS_ANY>. "<= Cette commande permet de typer le field symbol
Le cœur du programme sera donc.
SELECT *
INTO <FS_ANY> "<= variable générique typée dynamiquement avec le RTTS
FROM (TABLE) "<= Nom de la table lui aussi dynamique c'est à dire entre les parenthèses
WHERE (CLAUSE). "<= clause dynamique
Mais ce n’est pas fini, il faut ensuite lire les données récupérées dans la variable générique <FS_ANY>.
Pour cela il me faut un autre field-symbol de type générique pour lire les composants des tables appelons le <FS_COMP>.
FIELD-SYMBOLS : <FS_COMP> type ANY.
Il faut une boucle pour balayer un à un l’ensemble des champs de chaque structure et en récupérer la valeur.
DO.
ASSIGN COMPONENT SY-INDEX OF STRUCTURE <FS_ANY>
TO <FS_COMP>.
IF SY-SUBRC NE 0.
EXIT. "=> PLUS DE CHAMP A LIRE
ENDIF.
CHECK <FS_COMP> IS NOT INITIAL. "=> SAUTER LES CHAMPS VIDES
WRITE : <FS_COMP>. "POUR AFFICHER LA DONNEE. ENFIN !
ENDDO. En dernier, par mesure de précaution j’entoure tout le bloc du SELECT/ENDSELECT par une nouvelle clause TRY destinée à me protéger en cas de problème dans la clause de sélection. En effet il se peut que certaines instructions de la trace SQL ne soient pas formatées convenablement pour ce que je veux en faire. Je ne pourrais rien récupérer de ces lignes, mais au moins j’aurais évité le DUMP qui n’aurait pas manqué de se produire.
Pour terminer le programme, j’utiliserais un SELECT-OPTIONS pour passer les lignes des clauses à lire. C’est une manière simple de transférer les données du tableur vers SAP.
Voici le code complet
Il suffit de créer un programme exécutable avec SE80 puis de coller le texte suivant. Pour ma part je laisse ce genre de programme en objet local dans le package TMP car je ne vois pas ce qu’on pourrait en faire dans une autre instance que celle de développement.
*&---------------------------------------------------------------------*
*& Report ZST05_TRACE
*& Code PROJELLIA - 2013 - EXEMPLE LIVRE SANS GARANTIE DE FONCTIONNEMENT
*&---------------------------------------------------------------------*
*& Utilitaire pour visualiser le contenu des données suite à une trace
*& SQL réalisée avec ST05
*&---------------------------------------------------------------------*
REPORT zst05_data LINE-SIZE 1023.
DATA:
g512 TYPE char512.
SELECT-OPTIONS :
s_clause FOR g512 NO INTERVALS. "tableau des clauses de la trace SQL
PARAMETERS:
p_detail TYPE xfeld. "afficher le contenu des clauses avant de faire le SELECT
START-OF-SELECTION.
PERFORM get.
*&---------------------------------------------------------------------*
*& Form get
*&---------------------------------------------------------------------*
* Routine de lecture des clauses issues de la trace SQL
*----------------------------------------------------------------------*
FORM get.
DATA:
wdata TYPE REF TO data,
wpos TYPE i,
wtable TYPE char20,
wclause(512) TYPE c.
FIELD-SYMBOLS:
<fs_any> TYPE any,
<fs_comp> TYPE any.
LOOP AT s_clause.
FORMAT INTENSIFIED ON.
UNASSIGN <fs_any>.
* Decoder la clause contenue dans la trace du ST05
wclause = s_clause-low.
SEARCH wclause FOR 'SELECT WHERE'.
CHECK sy-fdpos GT 2. "=>
wpos = sy-fdpos.
wpos = wpos - 1.
wtable = wclause(wpos).
CHECK wtable IS NOT INITIAL. "=>
wpos = wpos + 15.
wclause = wclause+wpos.
SEARCH wclause FOR 'ORDER BY'.
IF sy-fdpos GT 0.
wclause = wclause(sy-fdpos).
ENDIF.
SEARCH wclause FOR 'FOR UPDATE'.
IF sy-fdpos GT 0.
wclause = wclause(sy-fdpos).
ENDIF.
* Créer la donnée avec le RTTS
TRY.
CLEAR wdata.
CREATE DATA wdata TYPE (wtable). "<= RTTS
CATCH cx_sy_create_data_error.
WRITE : / wtable COLOR COL_NEGATIVE,
'CREATE DATA' COLOR COL_NEGATIVE INTENSIFIED ON.
CONTINUE. "=>
ENDTRY.
IF wdata IS INITIAL.
WRITE : / wtable COLOR COL_NEGATIVE,
'DATA INITIALE' COLOR COL_NEGATIVE INTENSIFIED ON.
CONTINUE. "=>
ENDIF.
ASSIGN wdata->* TO <fs_any>.
IF <fs_any> IS NOT ASSIGNED.
WRITE : / wtable COLOR COL_NEGATIVE,
'NOT ASSIGNED' COLOR COL_NEGATIVE INTENSIFIED ON.
ENDIF.
TRANSLATE wclause USING '" '. "supprimer les guillemets autour des champs
IF p_detail IS NOT INITIAL.
WRITE : / wtable COLOR COL_KEY,
'CLAUSE:' COLOR COL_KEY INTENSIFIED ON, wclause.
ENDIF.
* Lecture des données
TRY.
SELECT *
INTO <fs_any>
FROM (wtable)
WHERE (wclause).
WRITE : / wtable COLOR COL_KEY.
FORMAT INTENSIFIED OFF.
DO.
ASSIGN COMPONENT sy-index OF STRUCTURE <fs_any>
TO <fs_comp>.
IF sy-subrc NE 0.
EXIT.
ENDIF.
CHECK <fs_comp> IS NOT INITIAL. "=>
WRITE : <fs_comp>. "<= ET VOILI, C'EST ICI QU'ON DESCEND !
ENDDO.
ENDSELECT.
IF sy-subrc NE 0.
IF p_detail IS NOT INITIAL.
CLEAR wclause.
ENDIF.
WRITE : / wtable COLOR COL_KEY,
'NO DATA' COLOR COL_GROUP INTENSIFIED ON,
wclause.
ENDIF.
CATCH : cx_sy_dynamic_osql_syntax,
cx_sy_dynamic_osql_semantics.
WRITE : / wtable COLOR COL_NEGATIVE INTENSIFIED ON,
'SELECT' COLOR COL_NEGATIVE, wclause.
ENDTRY.
ENDLOOP. "SCLAUSE
ENDFORM. "get
Et voilà une démo
Étape 1 : Récupération de la trace SQL [ST05] dans un fichier
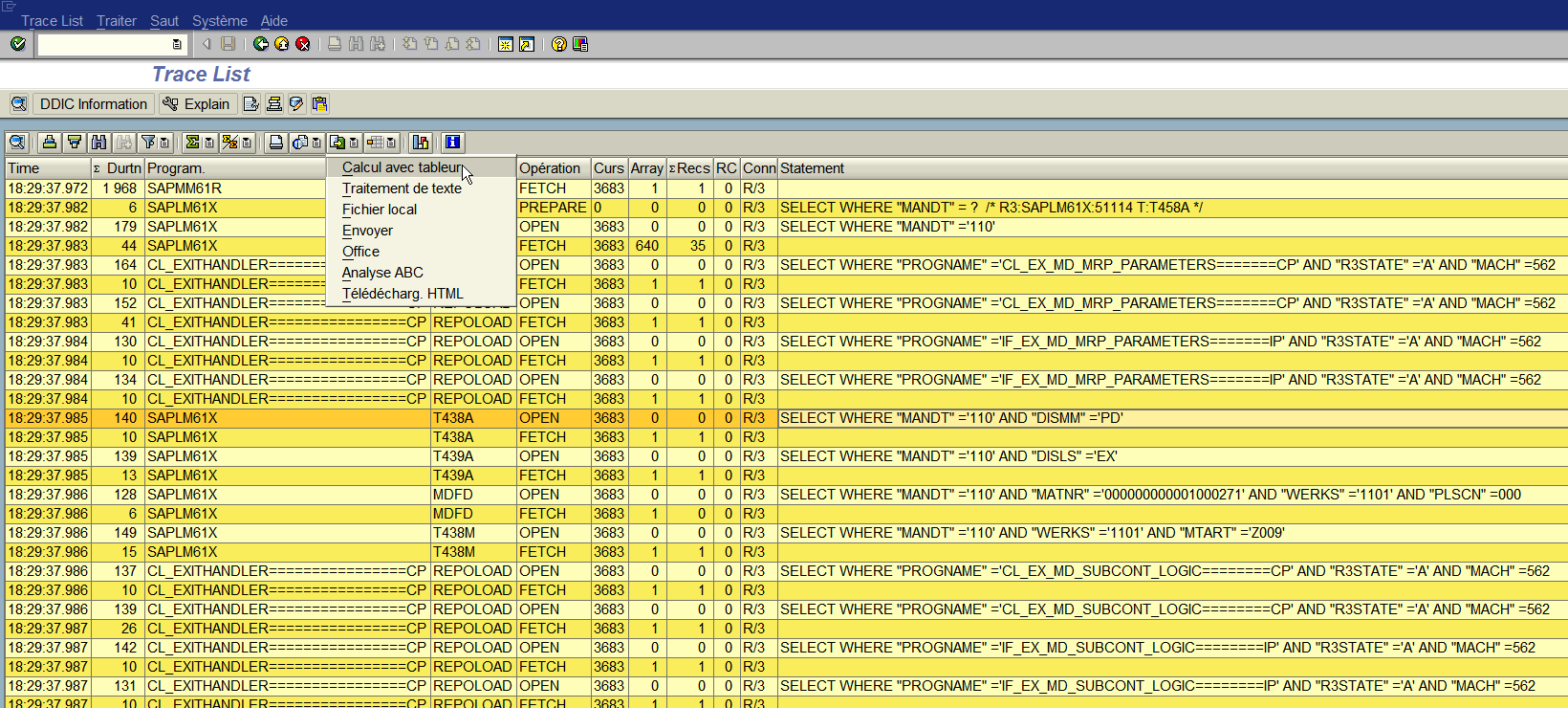
Étape 2 : Préparer le fichier
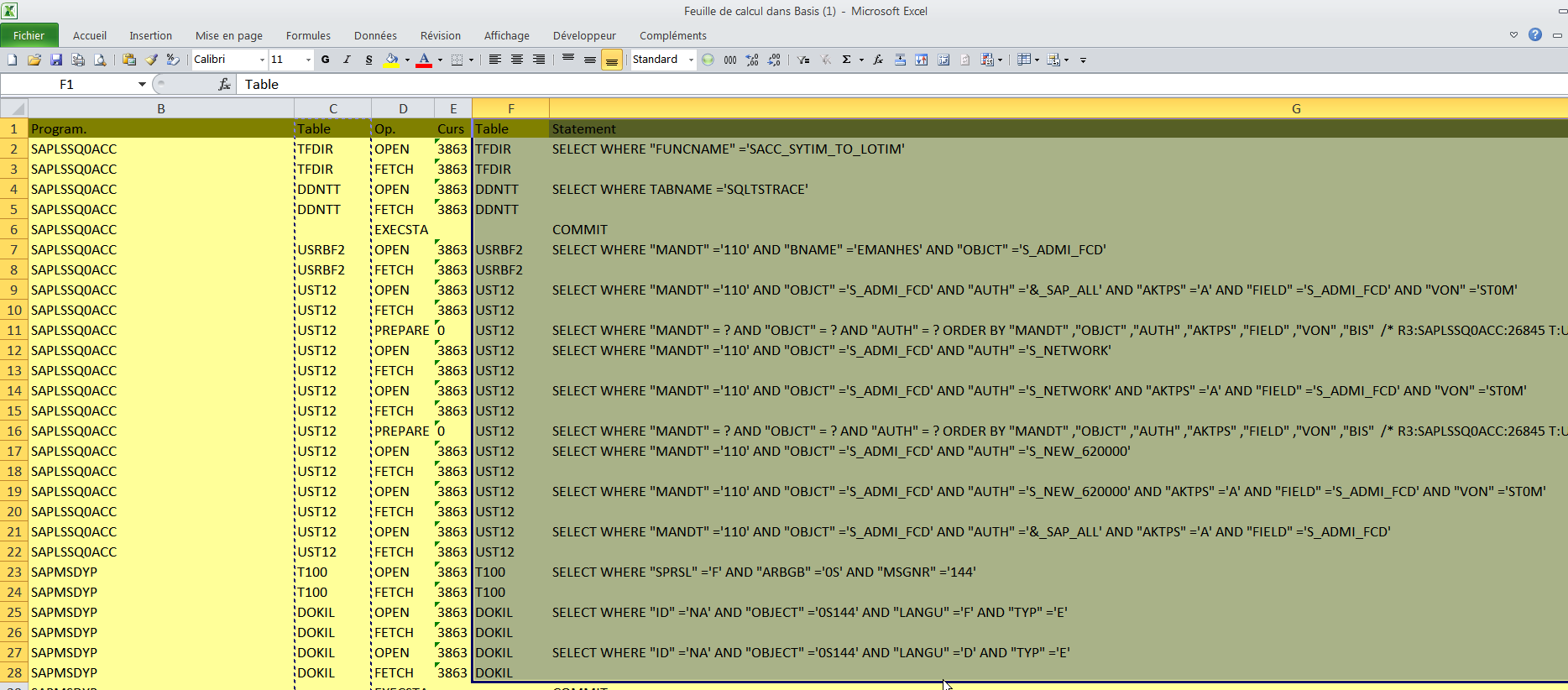
Ce qu’il faut c’est simplement mettre côte à côte les colonnes avec le nom des tables et les clauses de sélection. Une variante de mise en forme de l’ALV peut faire gagner du temps.
Ensuite il faut copier les deux colonnes dans le presse papier CTRL+C
Étape 3 : Lancer le programme et copier toutes les clauses
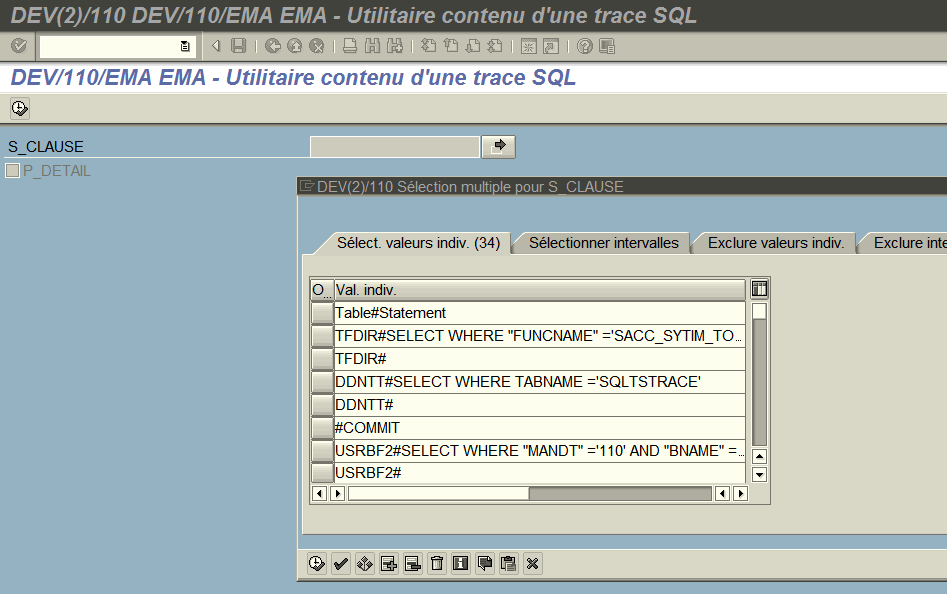
Il faut coller toutes les clauses dans le select option S_CLAUSE. Pour cela on utilise le bouton presse-papier (le 9ème bouton) et non pas Ctrl+V !
Étape 4 : Aller à la pèche aux infos !
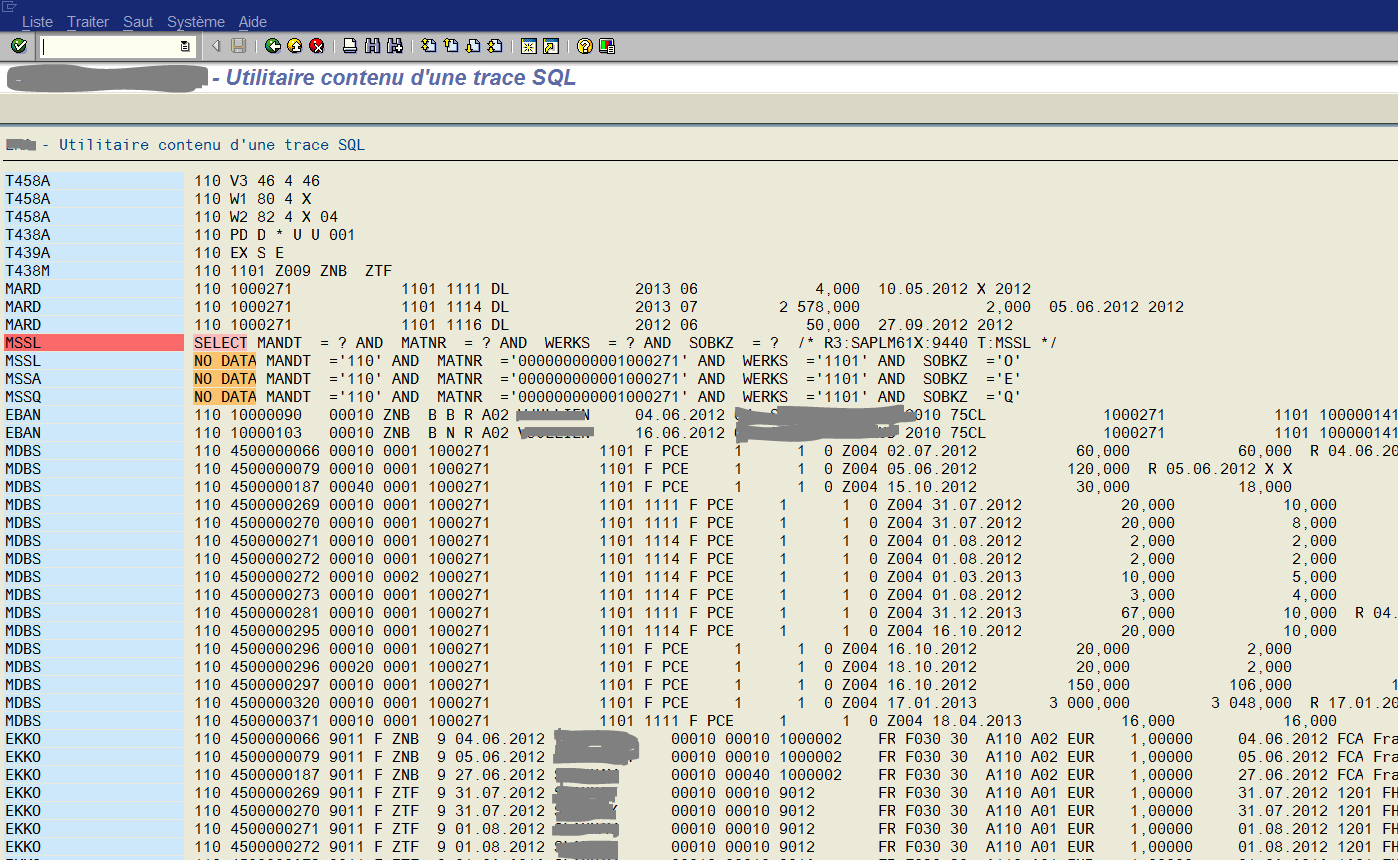
Attention c’est du brutal !
Premiers constats
De mon point de vue fournir un utilitaire cela consiste surtout à transmettre une astuce, pas un produit fini, bien léché. Je n’ai pas l’intention de séduire qui que ce soit avec le tableau final. Mais la démarche employée ici m’a semblé suffisamment intéressante pour être partagée (code et typage dynamique). Sans compter l’utilisation de la ST05 comme une sorte de loupe sur les données qui permet de se faire rapidement une idée assez précise de ce qu’il sera possible de faire.
Je vous encourage à faire évoluer ce code dans la direction qui vous semblera souhaitable. Pour ma part, j’ai bien l’intention de prolonger le travail, en améliorant le rendu visuel (et ce ne sera pas de trop) et surtout en connectant le programme directement aux traces mémorisées par SAP sans passer par l’export dans le fichier intermédiaire. Ceci me permettra d’afficher plus d’infos et, en particulier avec la version la plus évoluée de la ST05, afficher la pile d’appels pour visualiser rapidement les routines et fonctions impliquées dans la collecte des données. J’envisage aussi notamment de gérer encore plus de situations, par exemple pour la prise en compte des jointures de table car le programme actuel ne permet d’analyser que les accès mono-tables.
Dernière recommandation, n’oubliez pas que les données sont relues après coup et donc disponibles uniquement dans le dernier état connu. En particulier si vous avez fait une sauvegarde après modification d’un document, la trace aura enregistré les SELECT avant et après mise à jour, mais vous ne visualiserez que l’état après mise à jour, ce qu’il faudrait faire pour avoir avant/après ce serait une première extraction des données sans mise à jour, puis refaire une extraction avec la mise à jour.
A+
Eric